|
Socoder -> Blitz -> Using the Seekfile command |
|
| Mon, 18 Feb 2013, 22:06 | |
|
dna |
Here's a little snippet from my source. I was trying to move the to a specific record but I get varying results since each record can vary in length. For text such as: One_01 OneMore_02 Three_03 How should I resolve to move the pointer correct to pull an individual item? Thanks -=-=- DNA |
| Tue, 19 Feb 2013, 02:16 | |
waroffice
|
Looks like you need to move to a specific line not position, I cannot however remember how seekfile works at this time in the morning! Maybe it will come to me after my cup of tea. |
| Tue, 19 Feb 2013, 02:26 | |
|
Jayenkai |
SeekFile is byte based, not line based. In order to flick through lines, you need to literally flick through lines. Start at the start, read X lines 'til you get to the right one, that's the one. Alternatively, if you know the length of the lines when starting to write the file in the first place, you could create a list of lengths at the start of the file which you could read in, and use to work out the byte position of the line that you're trying to read. This is messy, but works. -=-=- ''Load, Next List!'' |
| Tue, 19 Feb 2013, 04:28 | |
steve_ancell
|
I was gonna say something similar to what Jay just said but he already beat me to it.  Only one other thing I could suggest off the top of my head would be to use tags inside square brackets or something, (take a look at the following structure). You would be simply using ReadLine(#stream) until it matches a string that you are searching for, in this case the word 'Record' followed by the number after it, whether or not you include whitespace is up to you. Once the string is matched with what you are searching you would then use the appropriate file-reading commands to deal with the way you want the remaining data loaded. [Record 1] Record data goes here [End Record] [Record 2] Record data goes here [End Record] [Record 3] Record data goes here [End Record] And so on and so forth... [End Of Records] |edit| Come to think of it, you could combine what I just said with what Jay said by putting the record's actual data position in between thos tags, that would make searching a whole lot quicker. |edit| |
| Tue, 19 Feb 2013, 08:10 | |
|
Dabz |
XML springs to mind, is there not an XML userlib for BlitzPlus, would be a lot easier to handle and save a ton of faffing! Dabz -=-=- Intel Core i5 6400 2.7GHz, NVIDIA GeForce GTX 1070 (8GB), 8Gig DDR4 RAM, 256GB SSD, 1TB HDD, Windows 10 64bit |
| Tue, 19 Feb 2013, 08:27 | |
Jayenkai
|
!?! That's even more lines of crap! |
| Tue, 19 Feb 2013, 08:36 | |
9572AD
|
If it reads byte-by-byte, wouldn't you need to go old-school and either ensure each datum is the same bytelength or use a special character as a delimter?
-=-=- All the raw, animal magnetism of a rutabaga. |
| Tue, 19 Feb 2013, 09:07 | |
Afr0
|
 If it reads byte-by-byte, wouldn't you need to go old-school and either ensure each datum is the same bytelength or use a special character as a delimter? If it reads byte-by-byte, wouldn't you need to go old-school and either ensure each datum is the same bytelength or use a special character as a delimter?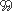 That's not "old-school", that's how reading is normally done under the hood in real (read: free, commonly used) languages. The most common delimiters are lengths of string added to the beginning of the string as a byte (these types of strings are called Pascal strings, because they first appeared in Pascal), the ASCII character '\0' at the end of a string (called a C-string) and the characters '\r\n' (used by Windows). -=-=- Afr0 Games Project Dollhouse on Github - Please fork! |
| Tue, 19 Feb 2013, 12:32 | |
|
dna |
Each record in the file is of a varying length. Using some sort of recognizable delimiter as some have suggested might be the solution. Which instruction is faster in machines cycles; Readline or readbyte? -=-=- DNA |
| Tue, 19 Feb 2013, 13:06 | |
|
Jayenkai |
Readbyte is faster, but the added looping that you'd have to manually do would completely kill any advantage of speed that it has over readline. -=-=- ''Load, Next List!'' |
| Tue, 19 Feb 2013, 13:09 | |
|
Afr0
|
Note that Readline(), IIRC, only reads ASCII text strings, and these are already delimited in Windows by \r\n.
-=-=- Afr0 Games Project Dollhouse on Github - Please fork! |
|
|
| |||
|
| ||||
Undock Sidebar
Log in
Register
Recent Uploads
spinal
angry dialog 01 test
spinal
angry dialog 01 test
spinal

glasses test
steve_ancell

IMG 202404 ... 104348 349
cyangames

snaphappy
Pakz
IMG 3178Spritegen
Pakz

IMG 0460Userint
spinal
nerdly error 1
spinal
blitz3d error array
Pakz

pixelArtPoster26x6
Log in
Register
Recent Uploads
spinal
angry dialog 01 test
spinal
angry dialog 01 test
spinal

glasses test
steve_ancell

IMG 202404 ... 104348 349
cyangames

snaphappy
Pakz
IMG 3178Spritegen
Pakz

IMG 0460Userint
spinal
nerdly error 1
spinal
blitz3d error array
Pakz
pixelArtPoster26x6